The MuCR Benchmark is used to assess MLLMs' cross-modal generalization on causal reasoning tasks.
Multimodal Large Language Models (MLLMs) have showcased exceptional Chain-of-Thought (CoT) reasoning ability in complex textual inference tasks including causal reasoning. However, will these causalities remain straightforward when crucial hints hide in visual details? If not, what factors might influence cross-modal generalization? Whether we can effectively enhance their capacity for robust causal inference across both text and vision? Motivated by these, we introduce MuCR - a novel Multimodal Causal Reasoning benchmark that leverages synthetic siamese images and text pairs to challenge MLLMs. Additionally, we develop tailored metrics from multiple perspectives, including image-level match, phrase-level understanding, and sentence-level explanation, to comprehensively assess MLLMs' comprehension abilities. Our experiments reveal that current MLLMs fall short in multimodal causal reasoning compared to their performance in purely textual settings. Additionally, we find that identifying visual cues across images is key to effective cross-modal generalization. Finally, we propose the VcCoT strategy that better highlights visual cues, and our results confirm its efficacy in enhancing multimodal causal reasoning.
We identify two major drawbacks in previous benchmarks:
(1) Absence of visual modality: Linguistic causal reasoning benchmarks fail to assess visual comprehension ability.
(2) Incomplete of cross-modal analysis: Existing causal reasoning VQA tasks often neglect or prove inadequate for cross-modal generalization analysis.
Our cause-and-effect image synthesis begins with generating core caption pairs, each consisting of one caption describing the cause and the other stating the effect. We then leverage the language capabilities of LLMs to entail these paired captions into contextually relevant descriptions, enhancing the consistency of sentences to facilitate the creation of cause-and-effect image pairs. Finally, we employ diffusion models to generate numerous siamese images based on these descriptions, annotating cue phrases and causality explanations for each pair.

Our MuCR benchmark consist 12k pairs of cause-and-effect images across various categories (humans, animals, plants, characters, and mixtures) and different styles (photograph, comic, and black-white). The below table illustrates some examples featuring various categories and styles from our MuCR benchmark as well as the distribution overview of categories and styles.

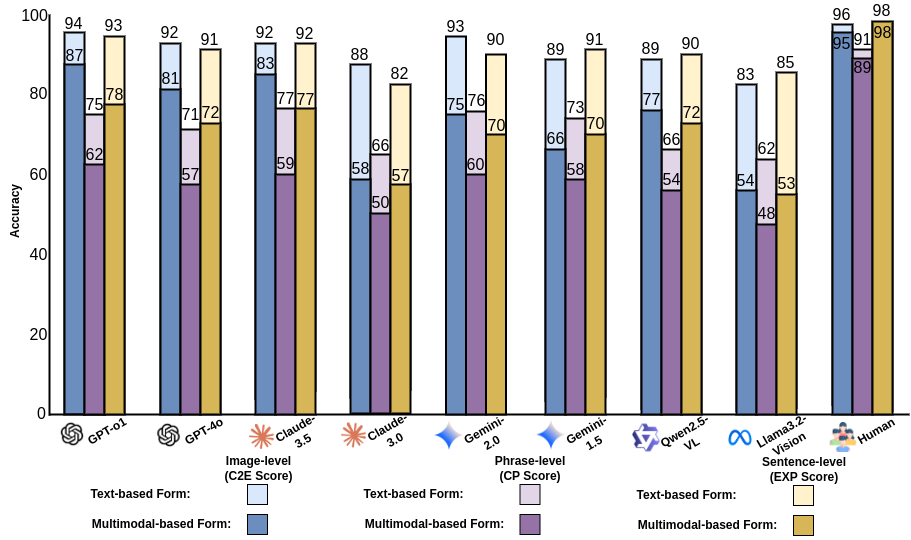
Image-level Metric. The image-level score consists of two parts: cause-to-effect (C2E) score and effect-to-cause (E2C) score. This scoring is designed to assess whether the VLLMs can identify visual cues and semantic causality between images and make the correct choice from four potential images (see paper for more details).
Phrase-level Metric. The phrase-level metric is called Cue score, which tests VLLMs' capability to distinguish the correct cue from a list of fraudulent phrases according to the siamese images (see paper for more details).
Sentence-level Metric. Our final metric is designed to evaluate VLLMs' ability to explain causality. This sentence-level metric is called the explanation (Exp) score (see paper for more details).
We evaluate several popular open-source models on our benchmark, including BLIP2, OpenFlamingo, InstructBLIP, MiniGPT4, and LLaVA. Additionally, we assess large-scale in-house models such as Claude, Gemini, and GPT-4. The models' performance is shown as below (see paper for more details).
This article is accepted by ACL2025 Findings
@article{li2024multimodal,
title={Multimodal Causal Reasoning Benchmark: Challenging Vision Large Language Models to Discern Causal Links Across Modalities},
author={Li, Zhiyuan and Wang, Heng and Liu, Dongnan and Zhang, Chaoyi and Ma, Ao and Long, Jieting and Cai, Weidong},
journal={arXiv preprint arXiv:2408.08105},
year={2024}
}
}